

Reliable Data Delivery In Kafka
Reliable Data Delivery In Kafka
Why we all love Kafka <3
What are the guarantees provided by Kafka?
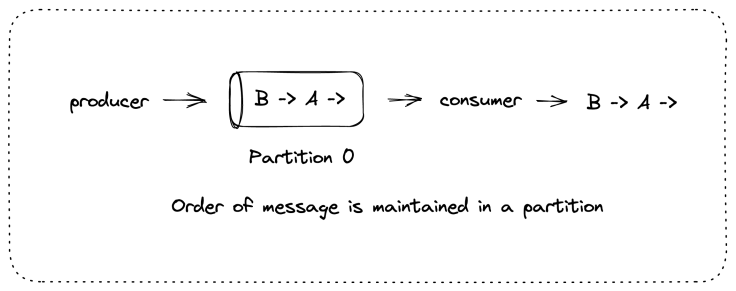
Guarantee of order
Assume that there are two messages – Message A and Message B.
Message B is sent after Message A by a producer. These messages are written in the same partition of a Kafka topic. In this case, Kafka guarantees that the offset of message B is more than message A. This also means that a consumer who is consuming from this particular partition will always consume message B after they have consumed message A.
Guarantee of commit
Producer messages are considered committed only when the message is written to the partition in all the in-sync replicas.
Producers can ask for acknowledgement at different levels –
when the message is sent over the network
when it is committed
or when it was written at the leader
Consumers can only read the message that is committed. Messages that are committed once will not be lost until there is at least one replica alive.
These basic guarantees can be used to design a reliable system. However, they alone are not sufficient. We live in a world of practicalities where infrastructure cost is limited (and therefore the number of replicas), traffic to the system is sometimes not predictable (and hence load on individual brokers), and so on. Hence the question arises- how can we make our system better in terms of reliability?
Reliability at the broker level
Replication Factor
You can create a topic with a topic-level configuration called replication.factor. If you choose to not specify the replication factor at the topic level, the topics are created with the default configuration which is specified at the broker level called the default.replication.factor.
Replication of N means that you can afford to lose N-1 brokers without affecting the read and write of data. That means that you have fewer disasters but you will have N brokers and more infrastructure costs.
But what is the right number of replicas for your Kafka topic?
It depends on how critical your application is. If you are okay with some data being lost when a broker is restarted, you may work with a replication factor of 1.
Banking applications may need a higher count of replicas so as to ensure high availability.
One way to think about the replica factor is how costly the unavailability of your topic is.
The topic which is processing click streams for sending promotional messages may be less critical than the topic which is processing banking transactions.
Unclean Leader Election
If the leader goes down and there are in-sync replicas available, one of the in-sync replicas will become the leader. But what happens when the leader goes down and there is no in-sync replica?
How can this happen?
Let’s assume there are three replicas. Two followers go down and then the producer continues writing to the leader. This makes the other two replicas out-of-sync. Now, if the leader goes down and one of the followers starts again. We will have an out-of-sync replica as the only available replica.
Assume that two followers out of three replicas lag in syncing with the leader. Meanwhile, the leader is accepting the requests of read and write. Now, if the leader goes down, two followers, out of which one could be the potential leader are essentially out of sync.
What options do we have now?
If we don’t allow these out-of-sync replicas to become the leader, we might have significant downtime which can hurt the business.
And if we allow one of these out-of-sync replicas to become the leader, we risk data loss and data inconsistencies. Imagine the two out-of-sync replicas have offset from 2000-3000 and the leader has reached the offset of 4000. Now, if the leader goes down and one of the out-of-sync replicas becomes leader, offset in the new leader will start from 3001. Consumers who have already read data till 4000, will not read the new data from offset 3001 to 4000 in the new leader. This will lead to data inconsistency.
The unclean election is the configuration where we allow out-of-sync replicas to become leader. This configuration is done by setting unclean.leader.election.enable flag to true. This flag is set to false where data quality and consistency is critical.
Minimum In-Sync Replicas
As per Kafka reliability guarantees, data is considered committed when it is written to all in-sync replicas, even when all means just one replica and the data could be lost if that replica is unavailable. To make sure that committed data is written to more than one replica, the minimum number of in-sync replicas needed to certify that the message is indeed committed should be greater than 1.
This can be done by a configuration called min.insync.replicas. This configuration is set up at both topic as well as the broker level.
What happens when producers try to send a message when there is not enough number of in-sync replicas?
Producers will get the NotEnoughReplicasException.
Reliability at the producer level
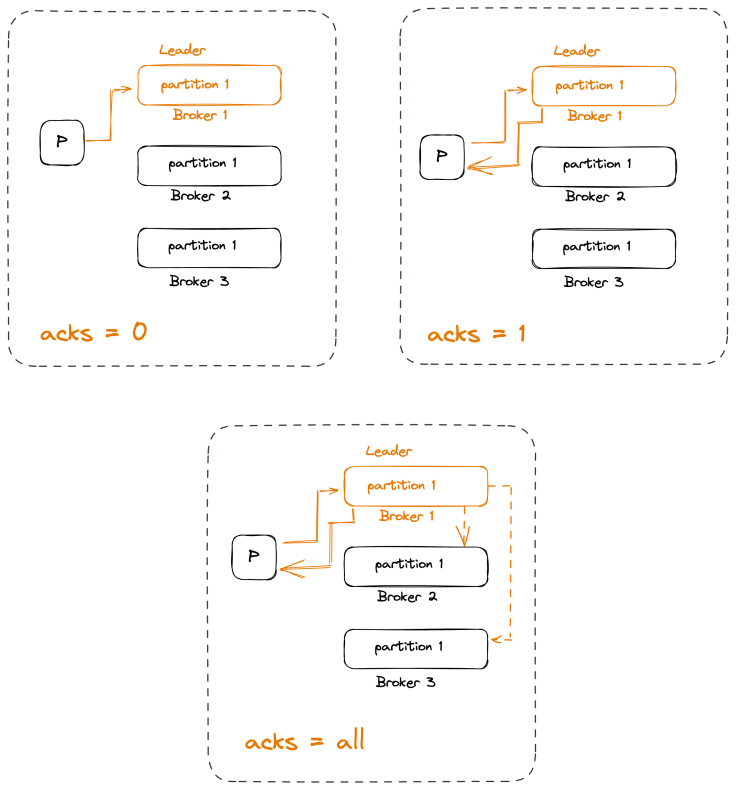
Send Acknowledgments
Producers can choose between three different acknowledgement modes:
acks=0
This means that a message is considered to be written successfully to Kafka if the producer managed to send it over the network. We will get a serialization error but we won’t get an error if the Kafka cluster is down.
acks=1
This means that the leader will send either an acknowledgement or an error the moment it got the message and wrote it to the partition data file. We can lose data if the leader crashes and some messages that were successfully written to the leader and acknowledged were not replicated to the followers before the crash.
acks=all
This means that the leader will wait until all in-sync replicas got the message before sending back an acknowledgement or an error.
Configuring Producer Retries
There are two parts to handling errors in the producer:
The errors that the producers handle automatically. Errors like LEADER_NOT_AVAILABLE are retriable as the leader might be available if retried.
The errors that you as the developer using the producer library must handle. Errors like INVALID_CONFIG have to be handled by developers as these have to be fixed first by the developers before they can be retried.
Retries and careful error handling can guarantee that each message will be stored at least once, but we can’t guarantee it will be stored exactly once.
Applications make the messages idempotent—meaning that even if the same message is sent twice, it has no negative impact on correctness.
Reliability at the consumer level
To ensure data reliability, we need to take care of the following configurations:
group.id
The basic idea is that if two consumers have the same group ID and subscribe to the same topic, each will be assigned a subset of the partitions in the topic and will therefore only read a subset of the messages individually but all the messages will be read by the group as a whole.
auto.offset.reset
This can have two possible values – latest and earliest.
When the consumer has just started, it does not know what offset it has to ask for. In this scenario, if the value of this flag is set as earliest, then the consumer will start consuming from the first message that the partition has. On the other hand, if the value of the flag is set as the latest, then the consumer will start consuming from the current message that has been committed in the partition.
enable.auto.commit
Offset has to be committed. Period.
The real question is when?
If we set the enable.auto.commit flag as true, the consumer will automatically commit the offset after the time interval specified in auto.commit.interval.ms flag.
Suppose we are committing the offset every 5 seconds and 3 seconds after the last commit, the server goes down. When the server comes back up, all the events processed in these 3 seconds will be re-processed.
In general, committing more frequently adds some overhead but reduces the number of duplicates that can occur when a consumer stops.
As a general rule, we should always commit offsets after events are processed.
Handling Long Processing Times
In some versions of the Kafka consumer, we can’t stop polling for more than a few seconds. Even if you don’t want to process additional records, we must continue polling so that the client can send heartbeats to the broker.
A common pattern in these cases is to hand off the data to a thread pool whenever possible with multiple threads, to speed things up a bit by processing in parallel. After handing off the records to the worker threads, you can pause the consumer and keep polling without actually fetching additional data until the worker threads finish. Once they are done, we can resume the consumer.
Because the consumer never stops polling, the heartbeat will be sent as planned and rebalancing will not be triggered.